HDFS & Its Architecture
HDFS & Its Architecture
HDFS - Hadoop Distributed System
HDFS is a file system designed for
storing very large files with streaming data access patterns running on
clusters of commoditive hardware.
Inspired from Google File System which was developed
using C++ during 2003 by Google to enhance its search engine, Hadoop
Distributed File System (HDFS), a Java based file system, becomes the core
components of Hadoop. With its fault tolerant and self-healing features, HDFS
enables Hadoop to harness the true capability of distributed processing
techniques by turning a cluster of industry standard servers or commodity
servers into massively scalable pool of storage. Just to add another feather in
its cap, HDFS can store structured, semi-structured or unstructured data in any
format regardless of schema and is specially designed to work in an environment
where scalability and throughput is critical.

HDFS Concepts
Blocks
A block of HDFS is 64MB, it is much more
than a disk (typical size 512 bytes).
HDFS blocks are large to minimize the cost
of seeks. By making a block large enough, the time to transfer the data from
the disk can be significantly longer than the time to seek the start of the
block.
Benefits for having a block abstraction
for a distributed file system:
·
File
can be larger than any disk in the network, so it can be stored on di↵erent
disks.
·
Unit
of abstraction a block rather than a file simplifies the storage subsystem (in
term of calculation the memory size). File metadata such as permissions
information does not need to be stored with the blocks.
To list the blocks that make up each
file in the filesystem. % hadoop fsck /
-files –blocks
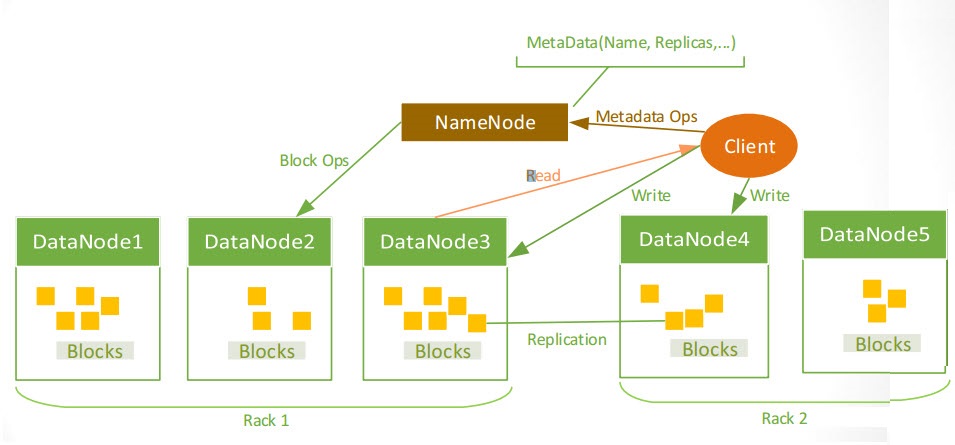
Namenodes and Datanodes
There are two types of nodes operating
in a master-worker pattern: a namenode and a number of datanodes, also called
master and workers. The namenode manages the filesystem namespace, maintains
the filesystem tree and the metadata for all the files and directories. The
namenode knows the datanodes on which all the blocks for a file are located. It
does not store block location persistently.
A client accesses the filesyestem by
communicating with both namenode and datanodes.
·
Datanodes
store and retrieve blocks when they are told to (by clients or by the
namenode), they report back to the namenode periodically with lists of blocks
that they are storing.
·
The
namenode is extremely important. It is essential to make the namenode resilient
to failure. There are two mechanisms for this.
·
Back
up the files that make up the persitaent state of the filesystem metadata.
Hadoop can be configured so that the namenode writes its persistent state to
multiple file systems. Usually, it writes to local disk as well as a remote NFS
mount.
·
Run
a secondary namenode which periodically merge the namespace image with the edit
log to prevent the edit log become too large.
Namespace and Block Storage
The namespace consists of directories,
files and blocks and supports all the namespace related file system operations
such as create, delete, modify and list files and directories.
The Block Storage Service has two parts
·
Block
Management (which is done in Namenode)
·
Storage
- is provided by datanodes by storing blocks on the local file system and
allows read/write access.
HDFS Federation
In order to scale the name service
horizontally, federation uses multiple independent Namenodes/namespaces. The
Namenodes are federated, that is, the Namenodes are independent and don’t
require coordination with each other. The datanodes are used as common storage
for blocks by all the Namenodes. Each datanode registers with all the Namenodes
in the cluster. Datanodes send periodic heartbeats and block reports and
handles commands from the Namenodes.

The entire Hadoop HDFS cluster is divided into two parts.
1. Master: This part of
cluster contains a node which is termed as Name Node. There can be one or
two optional Node which can be used for fault tolerance purpose which is termed
as Secondary / Standby Name Node.
2. Slave: All servers which
are a slave are called Data Node. The no of data node can be anything
which suits the business requirements. The size of data which can be hold
by HDFS in a cluster is decided by the data nodes disk size which is allocated
in HDFS. Any additional storage requirement can be fulfilled by just
adding one or more node of the required disk size.
Because Name Node is the central piece of the entire HDFS
cluster, it is essential to take a good care of this node. This machine
is recommended to be a good quality server with having lot of RAM. This
is the node which keeps mapping of “files to block” and “blocks to the data
nodes”. In short, Name node stores the file system metadata.

Basic Features
• Highly fault-tolerant
• Suitable for applications with large
data sets
• High throughput
• Streaming access to file system data
• Can be built out of commodity hardware
• Platform Independent
• Write-once-read-many: append is
supported
• A map-reduce application fits
perfectly with this model
Multi-Node Cluster
Master/slave architecture
Namenode
—
Single Namenode in a cluster
—
manages the file system namespace and regulates access to files by clients
Datanodes
—
A number of DataNodes usually one per node in a cluster
—
manage storage attached to the nodes that they run on
—
serve read/write requests, perform block creation, deletion and replication
upon instruction from Namenode
—
multiple DataNodes on the same machine is rare
Namenode
—
Keeps image of entire file system namespace and file Blockmap in memory
—
4GB of local RAM is sufficient
Periodic checkpointing
• gets the
FsImage and Editlog from its local file system at startup
• update FsImage
with EditLog information
• stores a copy
of the FsImage on filesytstem as a checkpoint
• the system can
recover back to the last checkpointed state in case of crash
EditLog
• a transaction
log to record every change that occurs to the filesystem metadata
FsImage
• stores file
system namespace with mapping of blocks to files and file system properties
Datanode
·
stores
data in files in its local file system
·
no
knowledge about HDFS filesystem
·
stores
each block of HDFS data in a separate file
·
Datanode
does not create all files in the same directory
·
heuristics
to determine optimal number of files per directory and create directories
appropriately:
File system Namespace
·
Hierarchical
file system with directories and files
·
Create,
remove, move, rename etc.
·
Namenode
maintains the file system Metadata
·
Any
meta information changes to the file system is recorded by the Namenode
·
number
of replicas of the file can be specified by application
·
replication
factor of the file is stored in the Namenode
Data Replication
·
each
file is a sequence of blocks
·
same
size blocks
·
for
fault tolerance
·
configurable
block size and replicas (per file)
·
a
Heartbeat and a BlockReport is sent to Namenode
·
Heartbeat
notifies activeness of Datanode
·
BlockReport
contains record of all the blocks on a Datanode
Replica Selection
·
to
minimize the bandwidth consumption and latency
·
local
replica node is most preferred
·
replica
in the local data center is preferred over the remote one
Replica Placement
·
Optimized
replica placement
·
Rack-aware
replica placement:
o
to
improve reliability, availability and network bandwidth utilization
·
Many
racks, communication between racks are through switches
·
Network
bandwidth is different
·
Replicas
are typically placed on unique racks
o
Simple
but non-optimal
o
Writes
are expensive
o
Replication
factor is 3
·
Replicas
are placed: one on a node in a local rack, one on a different node in the local
rack and one on a node in a different rack.
·
1/3
of the replica on a node, 2/3 on a rack and 1/3 distributed evenly across
remaining racks.
Namenode Startup
·
Safemode
·
Replication
is not possible
·
Each
DataNode checks in with Heartbeat and BlockReport
·
Namenode
verifies that each block has acceptable number of replicas
·
Namenode
exits Safemode
·
list
of blocks that need to be replicated.
·
Namenode
then proceeds to replicate these blocks to other Datanodes.

online trining for hadoop bigdata
ReplyDelete